最近和大黄,金岩,志强还有郝老师一起在筹备一个 Kaggle 语音识别的竞赛。数据是由 TensorFlow 提供,压缩后的训练集和测试集大约有 4 Gb 左右。我们五个基友虽然身在三个不同的国家,但大家依然踌躇满志的想要闷声搞点事情。
这个竞赛的目标是从一段长度为一秒钟的音频中,识别的单词。每段音频中都只包含一个单词,单词的种类一总有 33 种。比赛除了对识别准确率有要求之外,对运行的速度也有要求,能够在树莓派 ( Raspberry Pi 3 ) 上跑出来也会得到一个特别奖。
这篇博文主要介绍了一种对波形进行预处理的方法,预处理主要分为以下三个部分。由于比赛还在进行中,代码部分就不展示了。只是在这里介绍预处理的方法。
- 1,主要音频的提取,对杂音进行过滤
- 2,将开始和最末尾的没有信号的部分去除
- 3,降维和重采样
Data at A Glance
首先,我们导入数据来看一下,这些音频到底长什么样子吧。
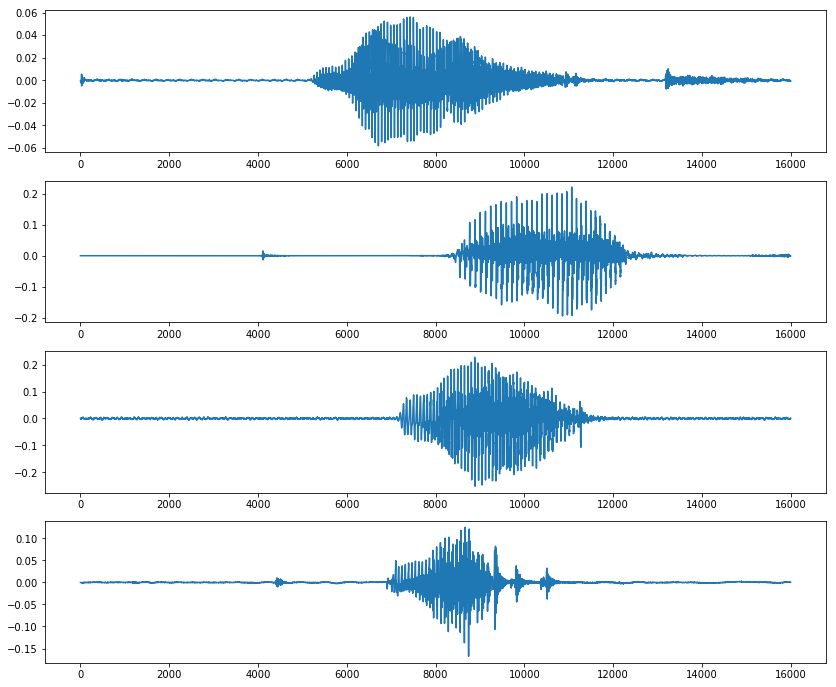
简单的扫一眼数据,我们会很容易的发现,如果我们直接的拿这个数据进行处理的话,会有以下的几个问题。而这些问题如果不矫正的话,很有可能导致最后训练的模型精度不高。
- 问题一:波形数据的分布非常不均匀,有的波形出现在音频快结束的时候,有的在中间,有的则在最开始。
- 问题二:开始和结束有很长时间的数据是没有声音的。
- 问题三:有一些wav中在除了主体的波之外的位置,有一些小的波,而这些短音频非常可能是外界的噪音。
这也让我有了想来对波形数据进行一些预处理的想法。
Keep Main Voice Only
第一个预处理,就是对杂音的处理。让我们首先来看一个有代表性的例子,很明显的能够看出来,在这个波频里面,有至少两段不同的声音,显然长的那一部分是对应发音的声音,而短的部分应该是外界的噪音。

现在我们的主要目标是能够将主要的声音提取出来,将其他的声音抹去,采用的方法如下。

将一整段波分成好多个等长的部分,通过平均值来决定是否是有声音或者是没声音,我们用每个小段的声音振幅的平均值,来判断这一段时间,是有声音还是没有声音的。设定一个阈值,均值小于它的就没声音,大于它的就是有声音。是用数组来表示的话,就是一串0,1的数字,0代表没有声音,而1代表有声音。形象一点用图像来表示,图中的绿色部分是有声音的,而蓝色部分是没有声音的。
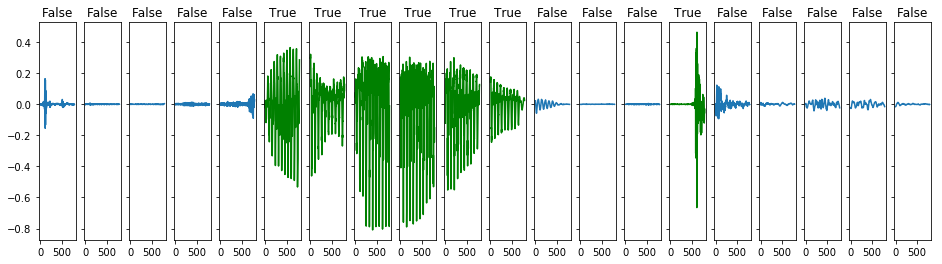
很显然,图中最长的连续的绿色的波,即是我们需要的数据,我们现在需要把它分离出来。为了防止前面和后面的小波段仍含有部分主声音的信息,但是由于被其他声音中和而均值没有达到阈值,我们也需要将它加入到最后过滤完的波里面来。
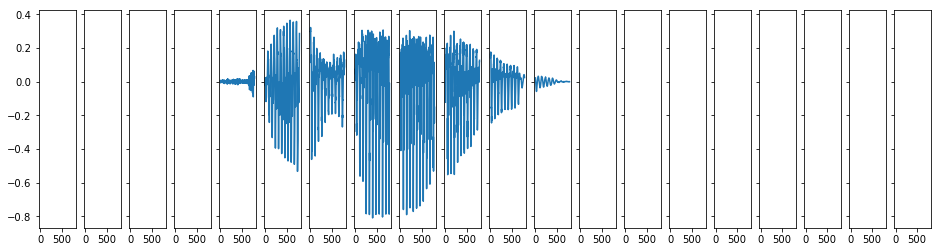
最后我们来看看这个预处理之后的结果如何。

可以看到,小的波形,噪音已经被过滤掉了,只留下了主要的波形。
Remove Silence
去除前面和后面的没有信号的部分,这一部分比较简单,主要是根据一个阈值来去除,小于阈值的就砍掉,直到到了第一个大于这个阈值的地方,就不砍了。处理完的结果如下图。

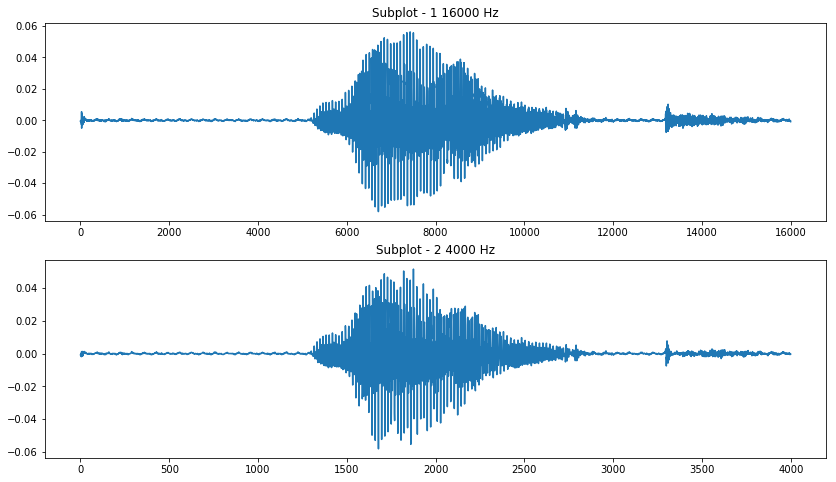
Resample Wav
这里主要是对时序数据进行重新采样,采样保留了波形的形状,同时可以降低数据的维度,计算更快,而且对于异常的数据,比如时间不为一秒钟的数据也能达到同样的维度。
Final Result
如果此时我们将三种预处理的方法合并到一起,对随机的几个wav数据进行处理,看看最后的结果如何。
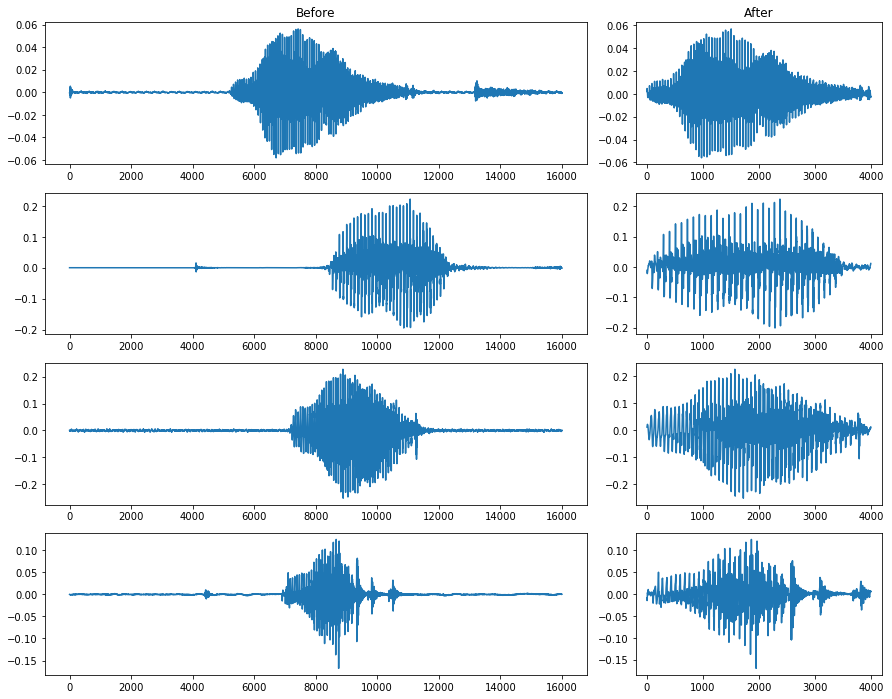
右边是处理后的波形,这时的波形几乎不包括杂音,我们使用的是真正的发出该单词的声音。而且声音的前后也没有 Silence。