这是 CNN 系列的第二篇,前面介绍了 LeNet5 和 AlexNet,所介绍的都是具有划时代意义的网络。这一期介绍的 GoogLeNet 和 VGG 也是具有很重要的意义的,有意思的是这两个网络均是 2014 同期发表出来的,分别是当时 ImageNet 的第一和第二名的模型。其中 VGG 网络获得了 ImageNet 定位的第一和分类的第二,GoogLeNet 获得了分类大赛的第一。不得不说 2014 年是 CNN 的丰收年。
如果说我们研究的是 “ 深度 ” 学习的话, 从 LeNet5 和 AlexNet 的身上,好像并没有感觉出来网络的深度感,因为他们分别只有 5层 和 8 层。但是从这一次介绍的 GoogLeNet 和 VGG 网络开始,网络的层数都开始有增加了,这不得不说是得益于 AlexNet 给与研究者的的深度能带来更好的效果的定心丸。
还是老样子,不想听我咯嗦介绍这些网络的。可以直接读源码去。
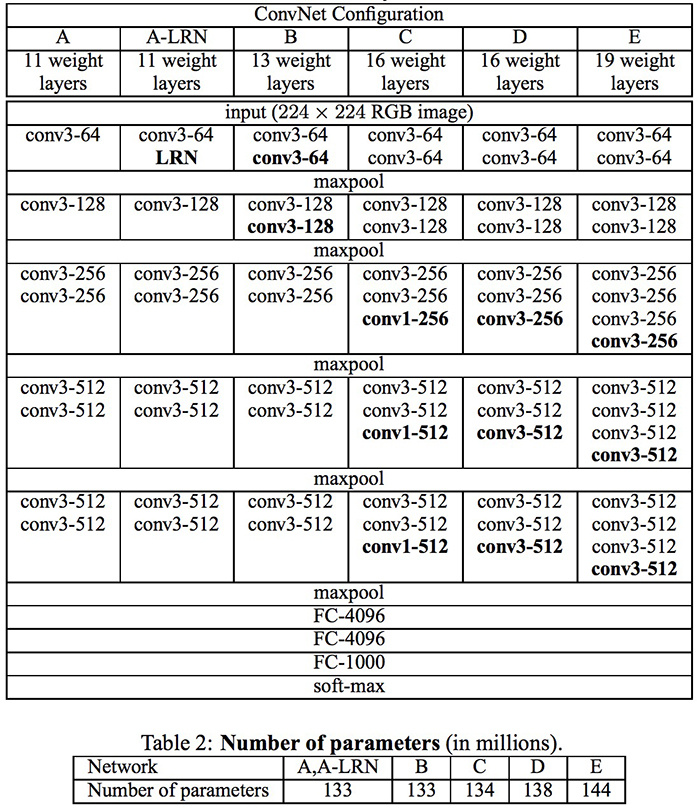
VGG(Simonyan and Zisseman, 2014)
首先来看一下 VGG-19 模型的层次关系图,来直观的感受一下深度学习中 “ 深度 ” 的含义。
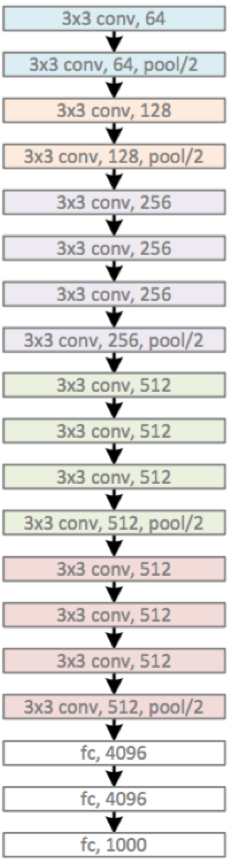
(si。。。 倒吸一口凉气,welcome to the world of DEEP learning)
不难从上图中看出 VGG 的特点就是四个字:“ 更小、更深 ”。
- 更小 : VGG 清一色使用 3 x 3 卷积。因为卷积不仅涉及到计算量,还影响到感受野。前者关系到是否方便部署到移动端、是否能满足实时处理、是否易于训练等,后者关系到参数更新、特征图的大小、特征是否提取的足够多、模型的复杂度和参数量等等。
- 更深 : VGG 提出 了 16 层网络和 19 层网络等更深的层次结构,并且取得了更好的效果,16 层的 VGG 网络 top-5 的 error rate 为 7.3%,而 8 层的 AlexNet 网络 top-5 的 error rate 为 15.3%,不得不说这是一个大的飞跃。
需要注意的是,VGG 有许多种不同的网络模型,且深度不一,其中效果最好的是 VGG-16 和 VGG-19.(即是最深的两个模型)
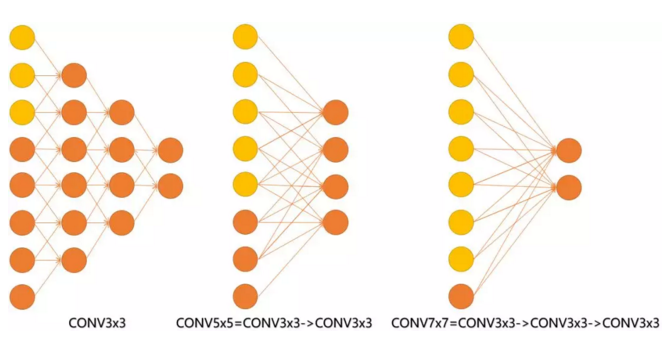
Why Small Kernel?
既然说到了 VGG 清一色用小卷积核,结合作者和自己的观点,这里整理出小卷积核比用大卷积核的三点优势:
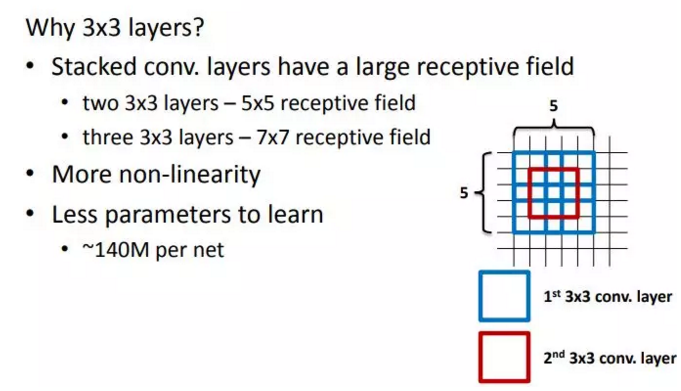
- 更大的视域能力。多的卷积核的使用可使决策函数更加具有辨别能力,此外就卷积本身的作用而言,3 x 3 比 7 x 7 更能捕获特征的变化:3 x 3 的 9 个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化。主要在于 3 个堆叠起来后,三个 3 x 3 近似一个 7 x 7。
- 更多的非线性函数。同样的卷积效果, 7 x 7 变成了 3 x 3 后,网络深了两层,且多出了两个非线性 ReLU 函数,使得判决函数更加具有判断性,对于不同类别的区分能力更强。
- 需要训练的参数变少了。相比 5 x 5 、7 x 7 和 11 x 11 的大卷积核, 3 x 3 明显地减少了参数量。比方 input channel 数和 output channel 数均为 C,那么 3 层 conv3 x 3 卷积所需要的卷积层参数是:3 x ( C x 3 x 3 x C ) = 27 C ^ 2,而一层conv7 x 7 卷积所需要的卷积层参数是:C x 7 x 7 x C = 49 C ^ 2。conv7 x 7 的卷积核参数比 conv3 x 3 多了 ( 49 - 27 ) / 27 x 100% ≈ 81%。
Pre-Trained VGG Model
由于 VGG 优良的性能,很多大赛均将 VGG 模型训练出来的结果作为 benchmark 来比较新算法的优劣。但是 VGG 那 100 多 million 的参数数量仍然是让人望而却步,适用于 ImageNet 的 VGG 模型,是在 4 个GPU 上训练了 3 - 4 周才得到较好的结果的。如果算上不停的实验,参数调优,真实的训练过程所需的时间会乘以 5 - 10 倍不止。
有没有方法能加快这个训练过程呢?答案是肯定的。
前面说到过 VGG 的优势在于超强的特征提取能力,所以我们可以做出以下假定,VGG 的卷积层,池化层,所做的事情都是进行特征提取,后面的全连接层,才是做的分类的任务。
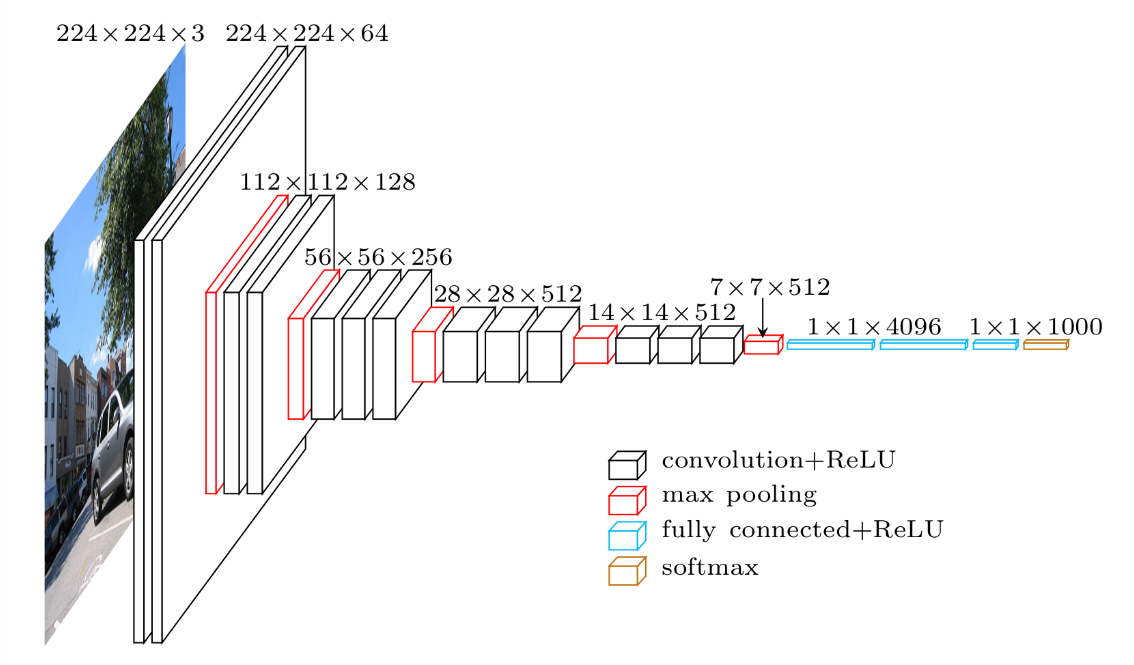
基于上面的假设,我们能做的事情就是,直接拿一个在别的项目上训练好了的模型参数,导入到新的任务中,但只是修改后面的分类器的参数(全连接层的权重矩阵和偏移变量,上图中的蓝色部分)。如此一来,需要训练的参数的数量大幅减少,训练也快了许多倍。
事实上,有很多人都是这么做的,最后发现效果都还不错。
网上有很多地方均可以下载到这些 pre trained model 的权重文件。
GoogLeNet (Christian Szegedy)
GoogLeNet 是 2014 年 ImageNet 的图像分类大赛的冠军。GoogLeNet 非常的厉害,为什么这么说呢?因为它实现了 6.67% 的 Top-5 错误率! 这与人类的表现非常接近,挑战的组织者在评估时证明,这种正确率实际上很难做到,并且需要一些人工训练才能击败 GoogLeNet 的准确性。人类专家(Andrej Karpathy),在经过几天的培训后,才能够达到 5.1%(single模式)和 3.6%(ensemble模式)的前5位错误率。
在正式的介绍 GoogLeNet 前,先介绍一个对 GoogLeNet 的出现有着重要推动作用的网络:
- Network in Network (Min Lin, 2013)
2013年年尾,Min Lin 提出了在卷积后,再跟一个 1x1 的卷积核对图像进行卷积的做法,这就是 Network In Network 的核心思想了。NiN 在每次卷积完之后使用,目的是为了在进入下一层的时候合并更多的特征参数。同样 NiN 层也是违背了 LeNet5 的设计原则(浅层网络使用大的卷积核),但却有效地合并卷积特征,减少网络参数、同样的内存可以存储更大的网络。
根据 Min Lin 的 NiN 论文,他们说这个“网络的网络”(NiN)能够提高 CNN 的局部感知区域。例如没有NiN的当前卷积是这样的:3x3 256 [conv] -> [maxpooling],当增加了NiN之后的卷积是这样的:3x3 256 [conv] -> 1x1 256 [conv] -> [maxpooling]。
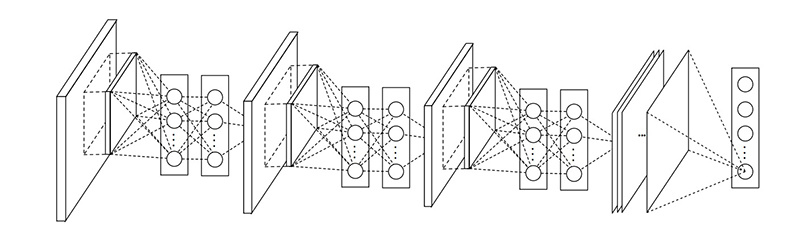
MLP多层感知的厉害之处就在于它把卷积特征结合起来成为一个更复杂的组合,这个思想将会在后面 ResNet 和 Inception 中用到。
Inception
GoogLeNet 又被称为 Inception-v1,那么 inception 到底是个什么东西呢?
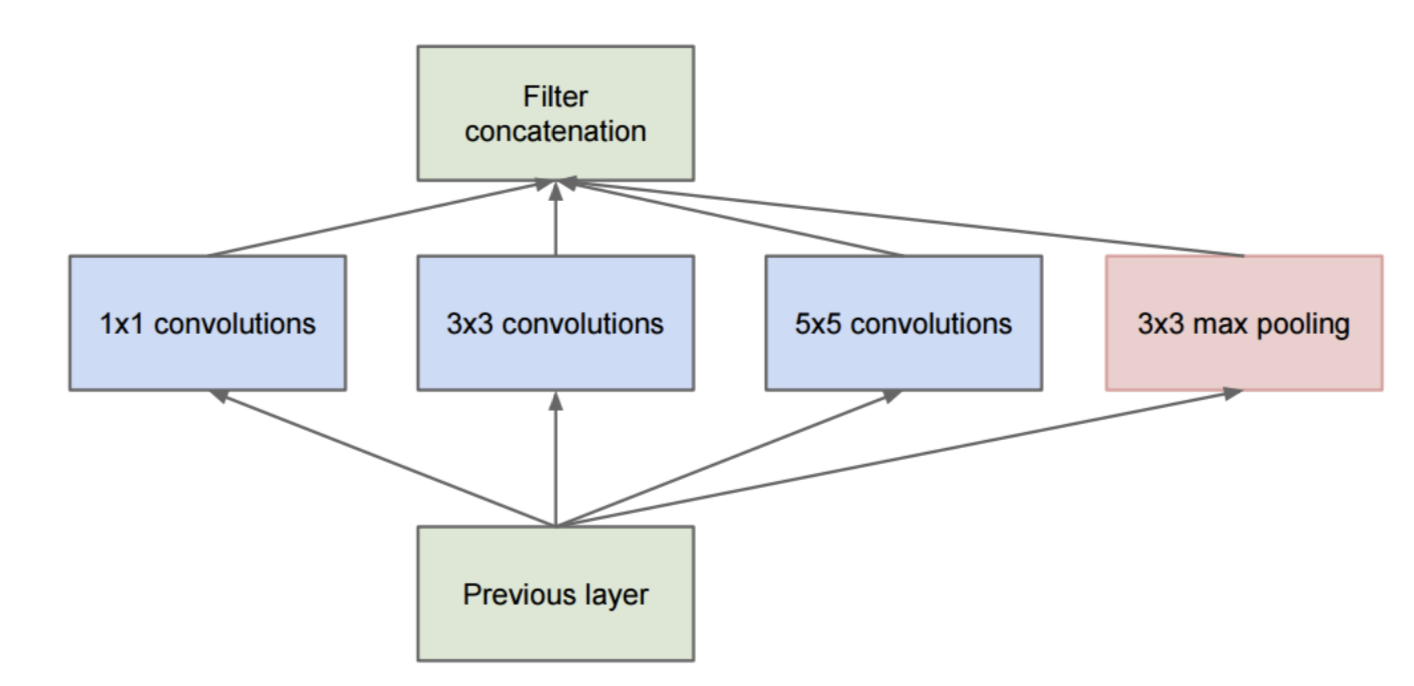
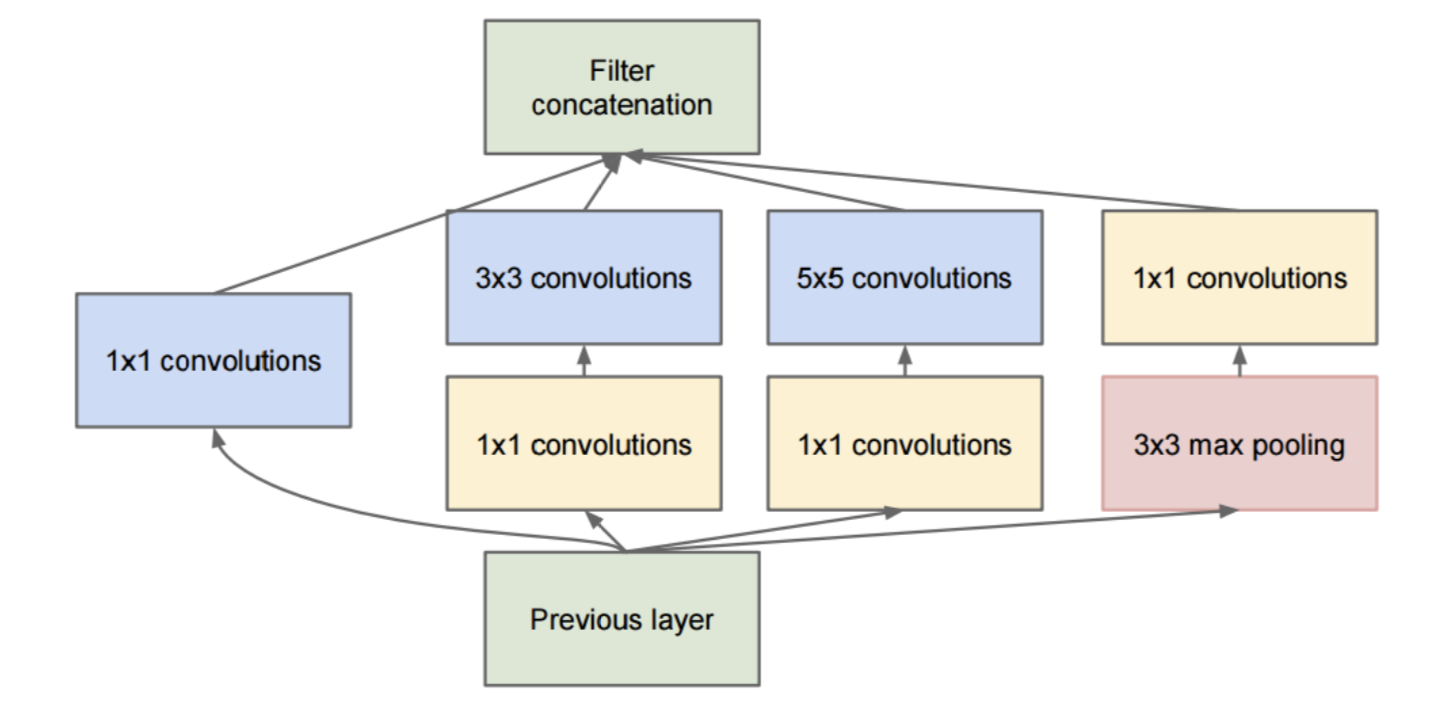
如果我们将 GoogLeNet 中的一些单元放大的话,就会发现有这么一个一分为四,四合而为一的结构,这个结构就是 Inception 。
那么这一种结构有什么好处呢?简单来说,有以下这么些好处。
- 1. 并行的进行不同视域大小的特征抽取。通俗点来说,我想做卷积,但是不知道这里是 1 x 1 的卷积好,还是 3 x 3 还是 5 x 5,不知道用哪个好的话,怎么办呢?那就一起用呗,于是就出现了下图这个 4 个并行路径的情况。
- 2. 更少的参数数量。那么细心的观众,可能发现了,真实的 GoogLeNet 中的 Inception 模块好像多了些东西?多了些什么呢?多的其实是一些 1 x 1 的卷积层,就像 VGG 中介绍的一样,小的卷积核先铺垫一遍后,可以做到很好的减少计算量的作用。相比于 AlexNet,GoogLeNet 的层次从 8 层增加到了 25 层,但是计算的参数数量却从 60 millions 降到了 4 millions。
- 3. Inception 具有更强的提取 feature 的能力。由于 1 x 1 卷积只有一个参数,相当于对原始 feature map 做了一个 scale,并且这个 scale 还是训练学出来的,无疑会对识别精度有提升。
为了直观的看一下,到底是怎么减少计算量的,这里附上李飞飞在 Stanford 上课时的课件。
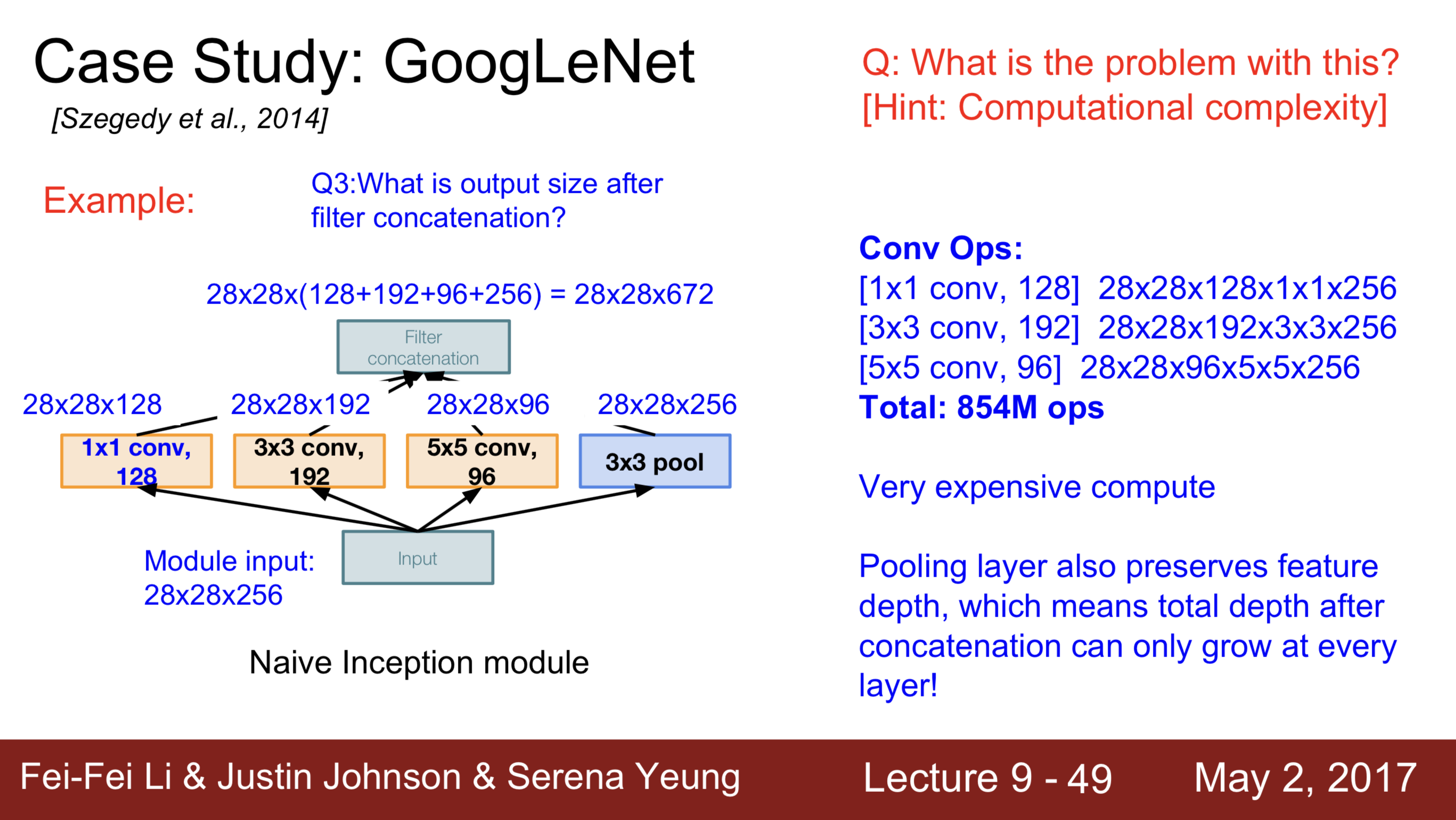
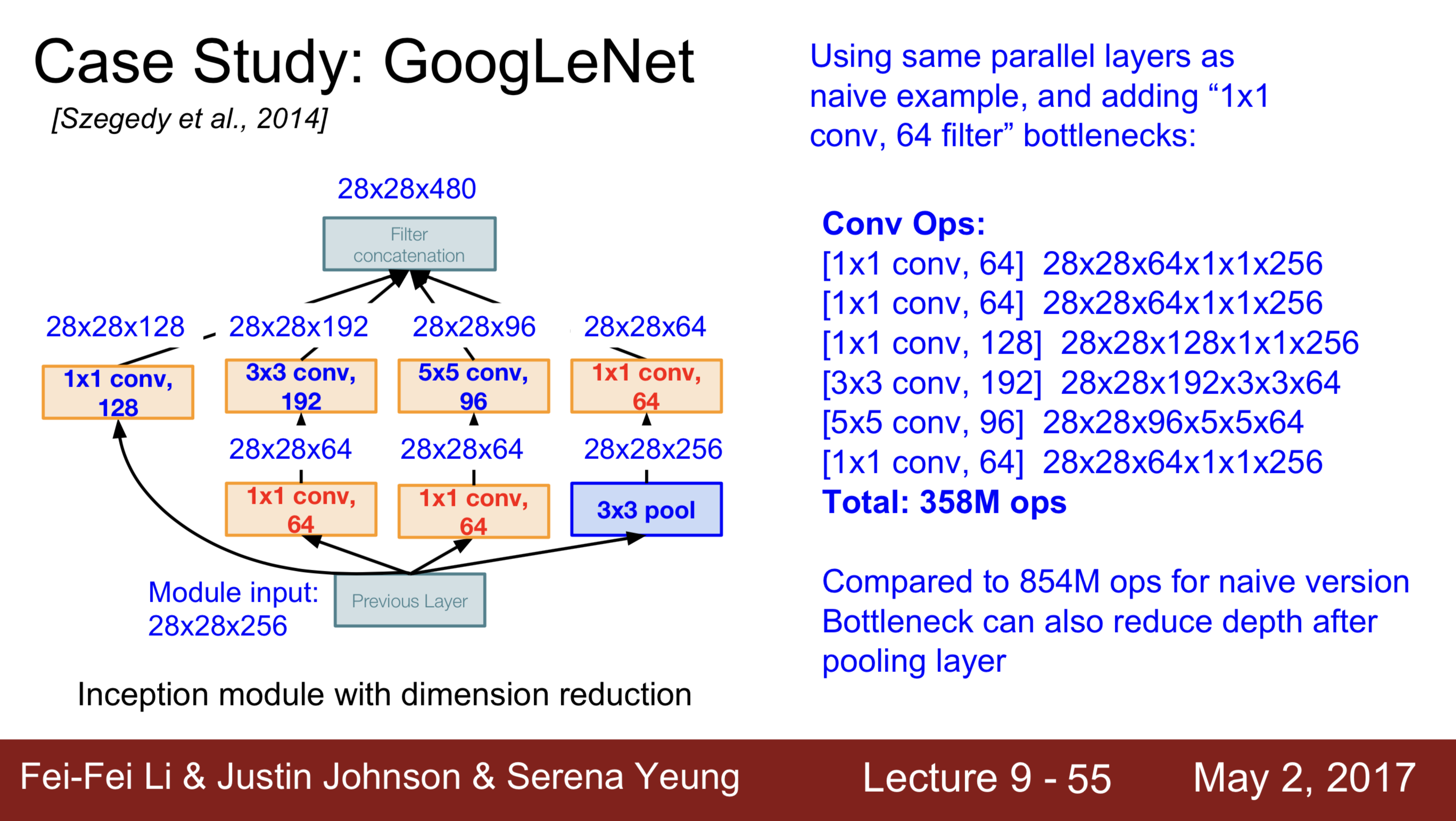
不难看出,简单一个 1 x 1 的卷积层,使得计算量从 854M 减少到了 358M。
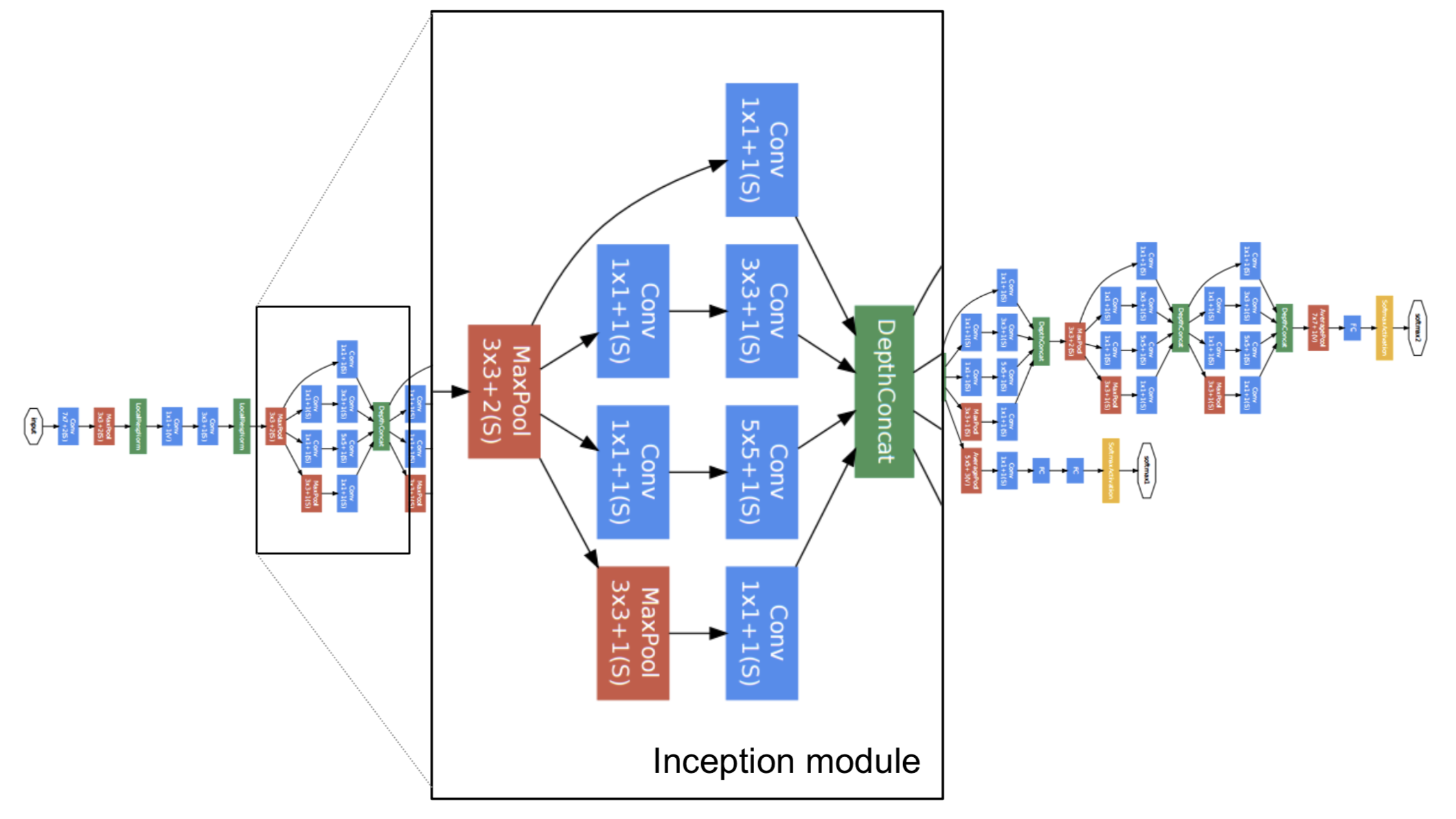
GoogLeNet Architecture
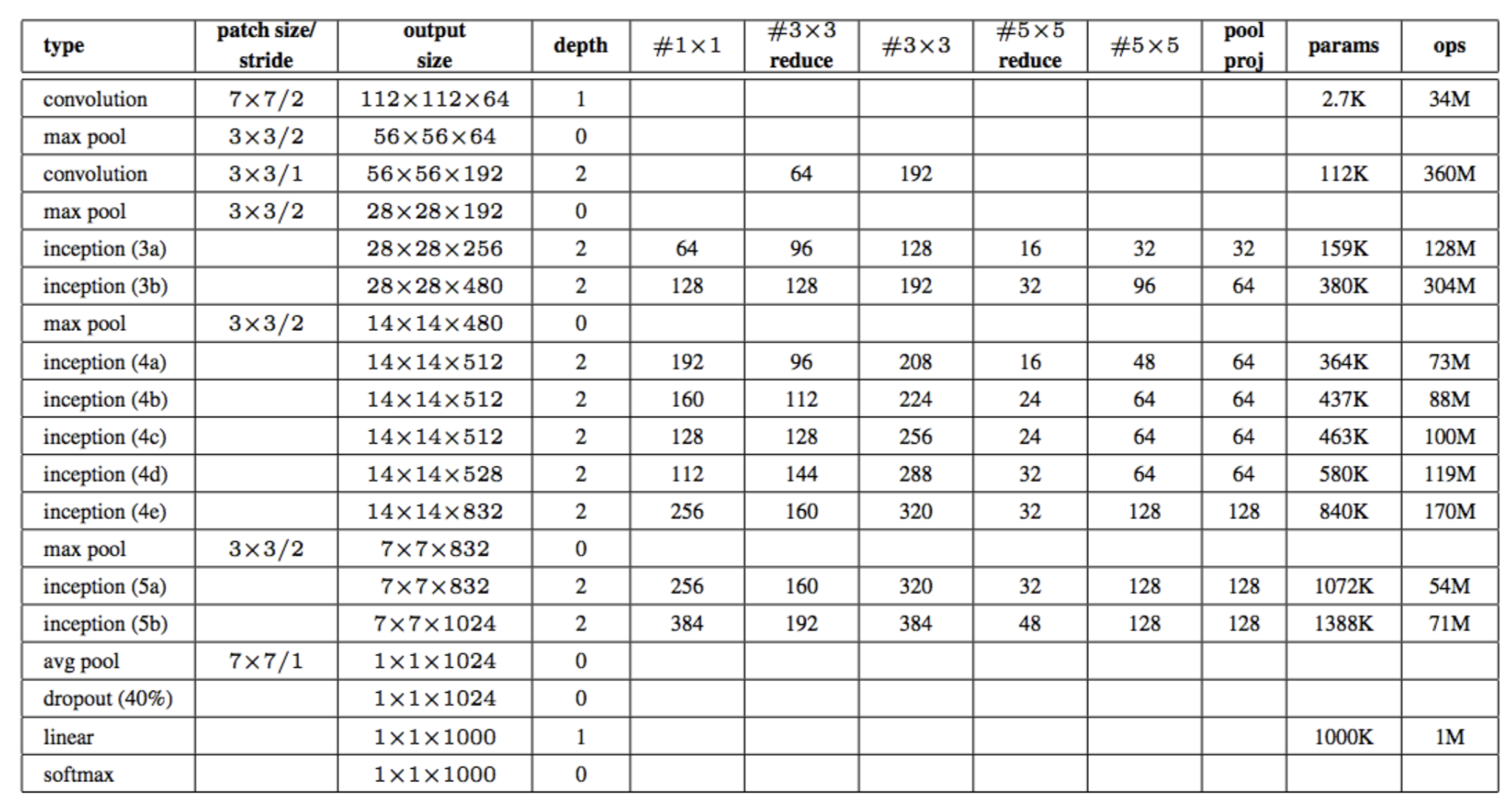
瞄一眼这个 GoogLeNet 的结构吧。这个图,在你自己动手实现这个网络的时候,很有用。(别问我怎么知道的。。。)
Auxiliary Layer
Auxiliary Layer 是从 GoogLeNet 中茬出来的一部分,大概是从第四部分的几个 Inception Module 中出来了两个中间分类的结果。
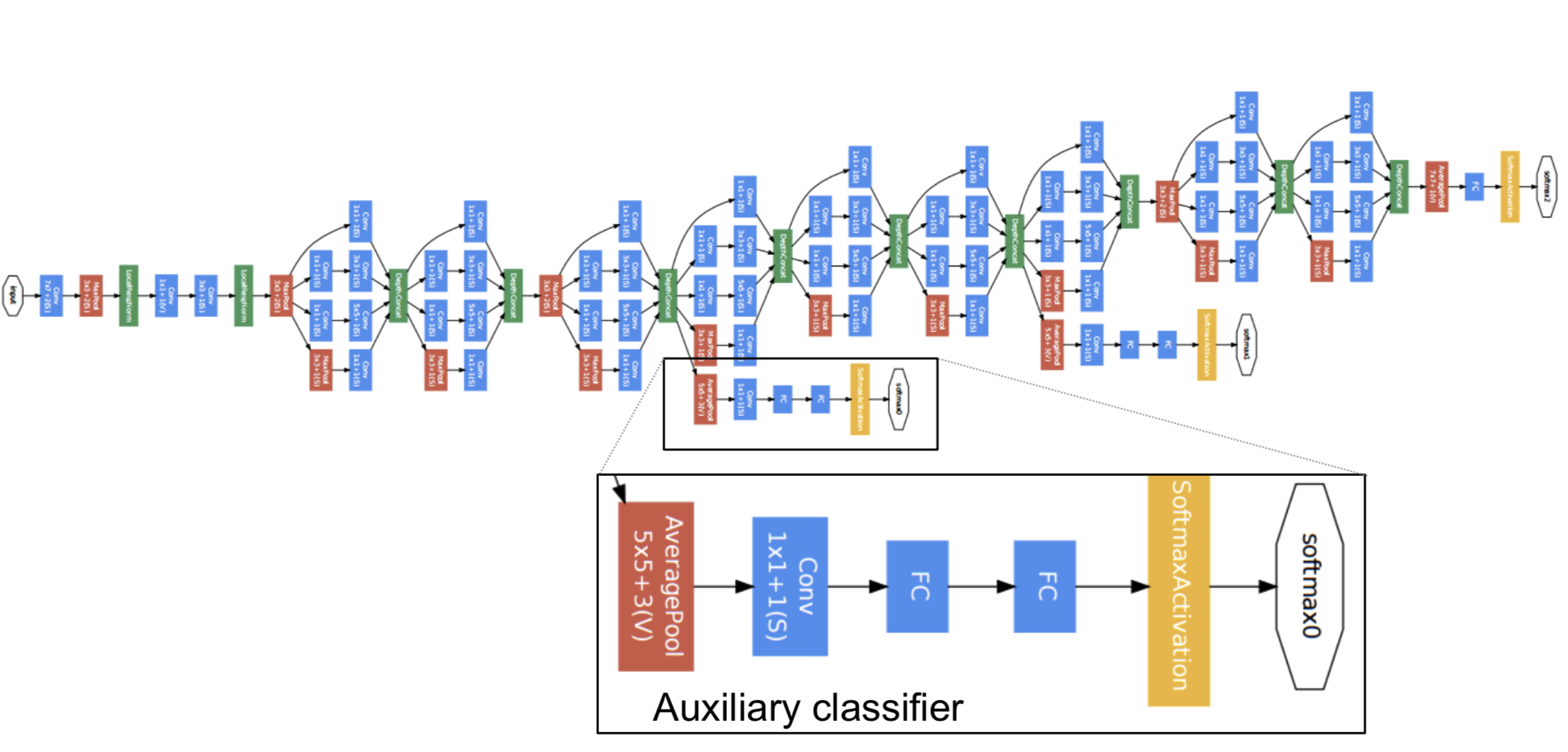
他们的作用是,为了平衡 loss。三个 classification loss(包括最后的主体输出),都会加入到梯度下降的计算中。这么做的好处是,能提高网络中层的辨识能力,通过 Auxiliary Layer 提取中低层特征,防止梯度消失,提供正则化。
At The End
好吧,这篇应该是我写博客以来,最长的一篇了。当然,我指的是图片的长度(毕竟那么多深网络示意图)。
(> - <)
Welcome to the world of '''DEEP LEARNING'''!!!