动了想写这篇博客的念头,原因有二,一来自己一直 focus 在 NLP 的研究和学习上,CNN 的算法多有耳闻,但一直处于知道那么一点点,好像听说过几个著名的网络的名字,但从来都没有系统的了解过这些算法,优劣性更是不知;二来是最近有看到一篇博客,介绍了各种网络的合集,觉得写得很不错,就想着要不自己拿 TensorFlow 把这些模型实现出来好了,正好好久没碰 TensorFlow 了,避免技能槽退化,时不时拿出来练练手也是极好的。
毕竟,不懂点 CV 的 NLP 攻城狮不是好的程序员。

这篇博客是 CNN 模型系列的第一篇,将会介绍 LeNet5 和 AlexNet,之后会持续更新 ResNet,GoogLeNet,VGG,SqueezeNet, Inception,Xception 等。当然,为了防止我做到后面,就忘了前面的,及时的写下自己所学,还是很有必要的。
不想听我啰嗦的,可以直接点击源码传送门。
LeNet5(Yann LeCun, 1998)
1998年,LeCun 大神发布了 LeNet 网络架构,从而揭开了深度学习的神秘面纱。从 1998 年开始,深度学习这一领域就开始不断地被人们所熟知,也是因为这个网络架构,不断地推动着深度学习这一领域。当然啦,为什么不叫 LeNet 而叫 LeNet5 呢,因为 Yann LeCun 经过了很多次反复的试验之后的结果,同时也因为有 5 个卷基层因此以 LeNet5 命名!
LeNet5 由两个卷积层,两个池化层,以及两个全连接层组成。 卷积都是5*5的模板,stride=1,池化都是MAX。下图是一个类似的结构,可以帮助理解层次结构。
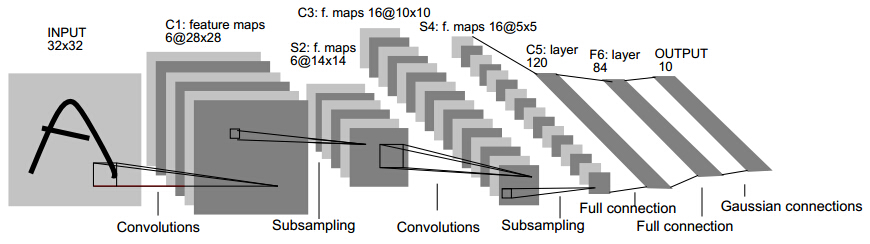
LeNet5 架构是一个开创性的工作,因为图像的特征是分布在整个图像当中的,并且学习参数利用卷积在相同参数的多个位置中提取相似特性的一种有效方法。回归到 1998 年当时没有 GPU 来帮助训练,甚至 CPU 速度都非常慢。因此,对比使用每个像素作为一个单独的输入的多层神经网络,LeNet5 能够节省参数和计算是一个关键的优势。LeNet5 论文中提到,全卷积不应该被放在第一层,因为图像中有着高度的空间相关性,并利用图像各个像素作为单独的输入特征不会利用这些相关性。因此有了CNN的三个特性了:1.局部感知、2.下采样、3.权值共享。
LeNet5 小结:
- 卷积神经网络使用3层架构:卷积、下采样、非线性激活函数
- 使用卷积提取图像空间特征
- 下采样使用了图像平均稀疏性
- 激活函数采用了tanh或者sigmoid函数
- 多层神经网络(MLP)作为最后的分类器
- 层之间使用稀疏连接矩阵,以避免大的计算成本
LeNet5 TensorFlow Implementation
这里的实现是基于经典的 MNIST 手写数字数据集来进行的。第一部分是根据前向传播,构建一个 5 层的神经网络。下面只展示核心代码部分,想看完整版的可以点击源码传送门。
def run(self):
"""
Run forward/backward propagation process of LeNet5 model
Evaluate on test set, get 98.5% accuracy.
# Layer 1:
# - a) Convolution: Input 32 * 32 * 1 , Output 28 * 28 * 6
# - b) Subsampling: Input 28 * 28 * 6 , Output 14 * 14 * 6
# Layer 2:
# - a) Convolution: Input 14 * 14 * 6 , Output 10 * 10 * 16
# - b) Subsampling: Input 10 * 10 * 16, Output 5 * 5 * 16
# Layer 3:
# - a) Flatten: Input 5 * 5 * 16, Output 120
# Layer 4:
# - a) Fully Connected: Input 120 , Output 84
# Layer 5:
# - a) Fully connected: Input 84 , Output 10
"""
##########################################################################
# Forward propagation
##########################################################################
# ==> Layer 1:
# - a) Convolution: Input 32 * 32 * 1 , Output 28 * 28 * 6
# - b) Subsampling: Input 28 * 28 * 6 , Output 14 * 14 * 6
conv_1 = tf.layers.conv2d(self.X, filters=6, kernel_size=5)
pool_1 = tf.layers.max_pooling2d(conv_1, pool_size=2, strides=2)
# ==> Layer 2:
# - a) Convolution: Input 14 * 14 * 6 , Output 10 * 10 * 16
# - b) Subsampling: Input 10 * 10 * 16, Output 5 * 5 * 16
conv_2 = tf.layers.conv2d(pool_1, filters=16, kernel_size=5)
pool_2 = tf.layers.max_pooling2d(conv_2, pool_size=2, strides=2)
# Flatten
# - a) Flatten: Input 5 * 5 * 16, Output 400
flatten = tf.layers.flatten(pool_2)
# ==> Layer 3:
# - a) Fully Connected: Input 400 , Output 120
full_1 = tf.layers.dense(flatten, units=120, activation=tf.nn.tanh)
# ==> Layer 4:
# - a) Fully Connected: Input 120 , Output 84
full_2 = tf.layers.dense(full_1, units=84, activation=tf.nn.tanh)
# ==> Layer 5:
# - a) Fully connected: Input 84 , Output 10
full_3 = tf.layers.dense(full_2, units=10, activation=tf.nn.sigmoid)
##########################################################################
# Backwards propagation
##########################################################################
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=self.y, logits=full_3)
loss = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(self.learning_rate)
train = optimizer.minimize(loss)
##########################################################################
# Compute accuracy
##########################################################################
corrects = tf.equal(tf.argmax(full_3, 1), tf.argmax(self.y, 1))
accuracy = tf.reduce_mean(tf.cast(corrects, tf.float32))
...AlexNet(Alex Krizhevsky, 2012)
2012年,Alex Krizhevsky 发表了 AlexNet,相对比 LeNet5 它的网络层次更加深,从 LeNet5 的 5 层到 AlexNet 的8层,更重要的是 AlexNet 还赢得了 2012 年的 ImageNet 竞赛的第一。AlexNet 不仅比 LeNet5 的神经网络层数更多更深,并且可以学习更复杂的图像高维特征。
模型结构见下图,别看只有寥寥八层(不算input层),但是它有60M以上的参数总量,事实上在参数量上比后面的网络都大。
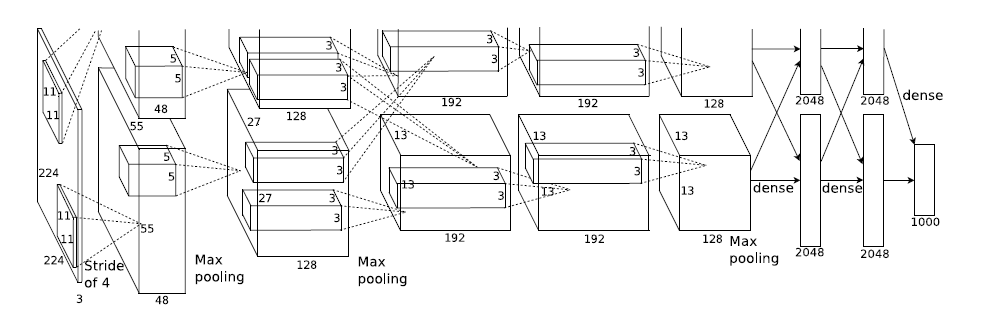
简单说一下 AlexNet 与众不同的地方,或者说具有划时代意义的点吧:
- 1. 使用了 ReLU 这个线性的激活函数。证明了线性激活函数一样可以做到和 tanh 和 signoid 相似的很好的效果。最重要的是,ReLU 函数的训练会快很多,经过 Alex 等人的实验, ReLU 的训练速度是 tanh 函数的 6 倍。
- 2. 使用 GPU 使得训练在可接受的范围内得到结果。在两个 NVIDIA GTX 580 3GB GPUs 上跑 90 个 epoch,仅需 5 - 6 天。(汗。。参数是有多大。。)
- 3. 证明了 CNN 在复杂模型下的有效性,让 CNN 大火了一把,推动了有监督 DL 的发展。
- 4. 提出了 Local Response Normalization (下面简称 LRN)这个 layer 的概念,有了这个层在,就避免了 ReLU 激活函数在后面出现两极分化,导致学不到东西的情况。
AlexNet TensorFlow Implementation
这里,我实现了一个 Simplified 的 AlexNet 模型,是基于 Stanford 公开课李飞飞介绍的一种架构。视频截图如下。

她里面还介绍了一些训练技巧,比如 data augmentation,我查阅了作者 Alex 在 NIPS 大会上的演讲的 PPT,他们的做法是先将图片 resize 成 256 * 256 * 3 的大小,然后随机的 shift 图像得到一个 227 * 227 * 3 的 array 作为 input。
然后在 learning rate 上面,他们玩的 decay 是如果一个 epoch 之后,loss 没有下降的话,learning rate 就除以十。
这些,我没有在我的代码中实现哈,因为 AlexNet 训练起来实在是太慢了,我的小 mac 基于 CPU 的根本就跑不起来,而且我还是只选了其中很少的一部分图像(7000张)做训练,完整的数据集有 15 000 000 张图像。。。 这些高级的操作,还是等我有设备了之后,再玩儿吧。
由于模型比较大,代码过长,这里只粘贴出了模型框架部分的注释,完整的代码戳这里。
"""
Run forward/backward propagation on AlexNet
# 1st convolutional layer: Input 227 * 227 * 3 , Output 55 * 55 * 96
# - a) Convolution Input 227 * 227 * 3 , Output 55 * 55 * 96
# - b) Normalization Input 55 * 55 * 96 , Output 55 * 55 * 96
# - c) Subsampling Input 55 * 55 * 96 , Output 27 * 27 * 96
# 2nd convolutional layer: Input 27 * 27 * 96 , Output 13 * 13 * 256
# - a) Convolution Input 27 * 27 * 96 , Output 27 * 27 * 256
# - b) Subsampling Input 27 * 27 * 256 , Output 13 * 13 * 256
# - c) Normalization Input 13 * 13 * 256 , Output 13 * 13 * 256
# 3rd convolutional layer: Input 13 * 13 * 256 , Output 13 * 13 * 384
# 4th convolutional layer: Input 13 * 13 * 384 , Output 13 * 13 * 384
# 5th convolutional layer: Input 13 * 13 * 384 , Output 13 * 13 * 256
# - a) Convolution Input 13 * 13 * 384 , Output 13 * 13 * 256
# - b) Subsampling Input 13 * 13 * 256 , Output 6 * 6 * 256
# Flattern layer: Input 6 * 6 * 256 , Output 9216
# 1st fully connected layer Input 9216 , Output 4906
# - a) Full Connected Input 9216 , Output 4906
# - b) Dropout Input 4906 , Output 4906
# 2nd fully connected layer Input 4906 , Output 4906
# - a) Full Connected Input 4906 , Output 4906
# - b) Dropout Input 4906 , Output 4906
# 3rd fully connected layer Input 4906 , Output 103
"""个人觉得,我的代码还是写的非常清晰和好懂的。起码比你在网上找的绝大多数的要好懂一些,当然了,我也是参考了许多他们的代码,然后进行的整理哈。
如果你是第一次跑的话。估计会跑很长时间,为什么呢,因为会需要下载大量大量的图片。。。。这个是很花时间的,等你下载好了之后,就好多了。
然后,如果看到虹色的 stderr,不要紧张,那基本都是些 tensorflow 的函数过期的警告,或者文件打不开的问题,文件打不开,我会自动跳过,读取下一张的,所以不要担心,只要没 exit,就没问题的。
如果你发现 accuracy 一直都是 0 或者 0.00*。不要惊讶,那是数据量不够造成的,想要得到好的效果,哈哈,在整个数据集上跑吧,跑它个三年五载去...
( > . < )
At The End
这只是个开始,接下来还有漫长的路程要走,CNN 博大精深。接下来还有好多模型等着我。不懂点 CV 的 NLP 攻城狮不是好的程序员。